Хочу выложить здесь некоторые обобщённые сведения о работе алгоритма Crypto1.
Сразу обозначу, что данный алгоритм является аппаратным, то есть он довольно жёсткий, хотя он со временем
был доработан .... Доработка эта была связана с теми ошибками, которые обнаружились в этом алгоритме. Эти
ошибки позволяли проводить атаки на метки с целью вскрытия ключей доступа. То есть, даже полностью закрытые
ключами доступа метки можно было вскрыть. И были разработаны специальные атаки для получения ключей
доступа. Атаки позволяли получить первый ключ (для полностью закрытой метки) а, затем, и ключи от всех секторов.
Для того чтобы понять на основе чего такое стало возможным надо немного разобраться как же функционирует
алгоритм Crypto1.
Как было описано в предыдущих моих статьях, посвящённых меткам Mifare Classic1K, эти метки имеют внутреннюю
память, состоящую из 16 секторов ( сектор состоит из 4-х блоков по 16 байт ). Каждый сектор может быть закрыт
6-байтными (48 бит) ключами доступа А и Б. Кроме того, каждый блок конфигурируется с помощью бит доступа.
Эти биты определяют что из себя представляет блок, какие ключи используются при чтении, записи блока и т. д.
Когда мы хотим начать работу с определённым блоком, то должны сначала произвести процедуру аутентификации.
Это 3-х проходная процедура, которая определяет совпадает ли ключ от сектора (в котором находится данный блок)
в метке с ключом, который есть в считывателе. Если ключи совпадут, то далее можно работать с данной меткой.
Теперь более подробно как это устроено.
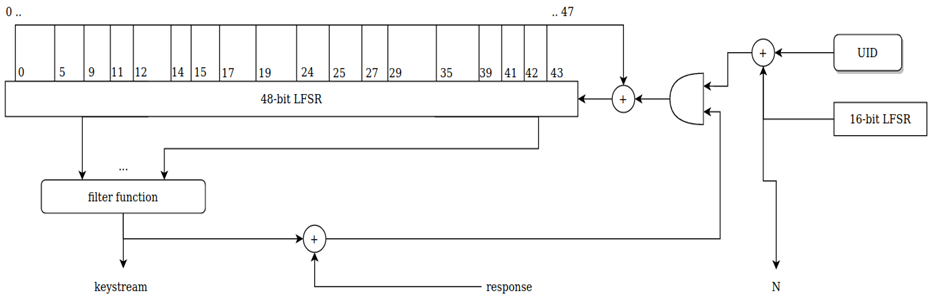
Работа процедуры аутентификации основана на работе 48-битного сдвигового регистра LFSR(48) с обратной связью и двухуровневой
фильтр-функцией. Этот фильтр берёт данные из регистра LFSR(48) и по определённому закону формирует на своём выходе бит ключевого
потока (Ks).
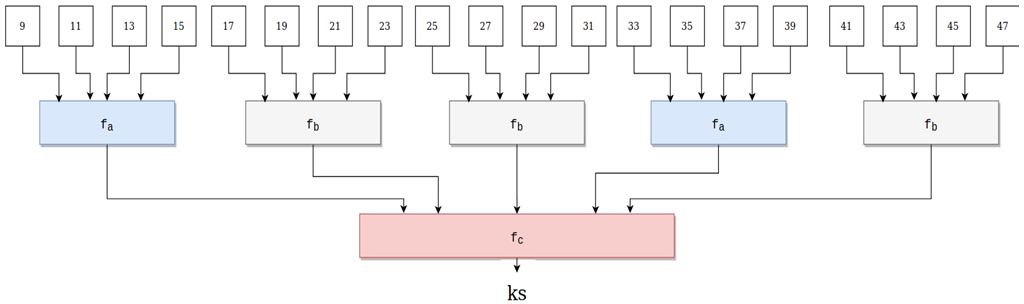
При сдвиге информации в регистре LFSR(48) на выходе фильтра формируется "ключевой поток" (Keystream).
Кроме этого есть и второй сдвиговый регистр LFSR(16), который формирует данные Nt, Nr, Ar, At на различных этапах работы.
Работа регистра одинакова как в метке, так и в считывателе !
Хочу отметить, что этот регистр имеет размер всего 16 бит а данные Nt, Nr, Ar, At имеют размер 32 бита. Поэтому
оставшиеся 16 бит дополнительно формируются по формуле X15 = (X0) XOR (X2) XOR (X3) XOR (X5) при сдвиге информации
в регистре LFSR(16) влево.
При этом в регистре LFSR(48) формируется новый бит 47 на основе операции XOR функции обратной связи и вводных данных,
а бит 0 в регистре LFSR(48) отбрасывается.
В начале аутентификации в регистр LFSR (48) (и в метке и в считывателе) загружается 48-ми битный ключ ( Key ).
В метку этот ключ прописывается при программировании на ПК с помощью специальной карты объекта ( КО ).
Считыватель переводится в защищённый режим с помощью этой же карты объекта ( КО ). Она задаёт правила расчёта
ключа доступа для метки в зависимости от её кода ( UID ).
В регистре LFSR(16) метки формируется случайным образом первоначальный одноразовый ключ ( Nt ).
В регистре UID считывателя и метки содержится 4-х байтный (32-битный) код метки.
Процедуру аутентификации можно рассмотреть на схеме:
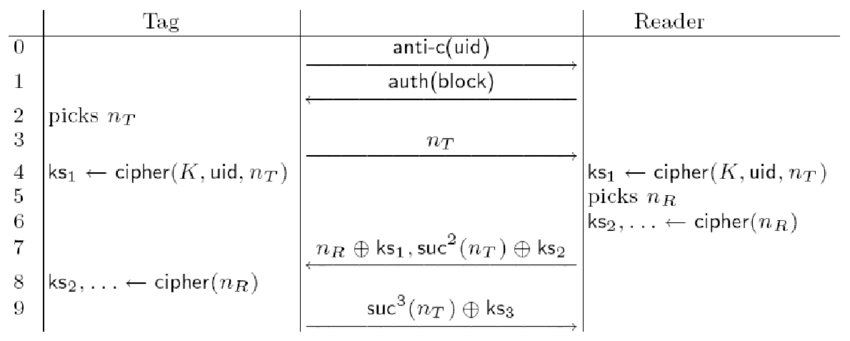
1. При поднесении метки к считывателю, она передаёт ему свой код идентификации ( UID ).
2. Считыватель выдаёт команду на аутентификацию к блоку памяти метки.
При этом в регистр LFSR(48) и в метке и в считывателе заносится ключ доступа сектора ( Key ), в котором
находится данный блок.
3. Метка передаёт считывателю сформированный в ней одноразовый ключ Nt.
Этот ключ передаётся в незашифрованном виде !
4. Считыватель помещает его в регистр LFSR(16) и производит сдвиг информации влево на 32 бита в регистрах
LFSR(48), LFSR(16) и UID.
При этом каждый новый бит, вдвигаемый справа LFSR(48) формируется как операция XOR между функцией
обратной связи регистра LFSR(48), левого бита регистра LFSR(16) и левого бита регистра UID.
При этом формируется 32-х битные ответ считывателя Nr и ключевой поток Ks1 на выходе фильтр-функции.
5. Далее производится сдвиг информации влево ещё на 32 бита регистра LFSR(48), LFSR(16).
При этом каждый новый бит, вдвигаемый справа LFSR(48) формируется как операция XOR между функцией
обратной связи регистра LFSR(48), левого бита регистра LFSR(16).
В результате получаем запрос считывателя к карте Ar и ключевой поток Ks2.
6. Информация к карте Nr и Ar передаётся не в явном виде. а в зашифрованном { Nr } и { Ar } где:
{ Nr } = Nr XOR Ks1
{ Ar } = Ar XOR Ks2
7. Карта на это производит со своей стороны сдвиг информации для расшифровки переданных данных.
Если всё нормально, то производится сдвиг информации в регистре LFSR(48) карты для формирования ответа
карты считывателю At и ключевого потока Ks3. При этом каждый новый бит регистра LFSR(48) получается за
счёт работы функции обратной связи этого регистра.
Ответ тоже шифруется { At } = At XOR Ks3 и передаётся на считыватель, который производит сдвиг информации
в своём регистре LFSR(48) на 32 бита и расшифровывает этот ответ.
Если всё нормально, то считается что аутентификация прошла успешно и начинается работа с блоком памяти
(чтение, запись и т. д.).
Ну вот так примерно всё и происходит при работе алгоритма шифрования Crypto1 в режиме аутентификации.
В дальнейшем попробую описать как же сумели вскрыть этот процесс шифрования и как работает расшифровка
ключей доступа.
Продолжение следует....
Ну, как и обещал, посмотрим как же можно узнать ключ от сектора...
Всё основывается на том, что при аутентификации в регистр LFSR(48) считывателя и метки загружается
ключ от сектора. Какой именно А или Б - это определяется командой на аутентификацию.
И то, что одноразовый ключ Nt передаётся от метки к считывателю незашифрованным.
А это значит, что сделав эмулятор ключа, который передаст считывателю UID метки и одноразовый Nt,
можно получить от него в ответ {Nr} и {Ar}. Мы, со своей стороны, можем на основе Nt получить
Nr и Ar. Отсюда можно получить ключевые потоки Ks1 и Ks2. Эти ключевые потоки получаются при
сдвиге регистра LFSR(48). Вот тут начинается самое интересное. Ключевой поток получается после
2-х уровневой функции, а нам надо получить то, что содержится в регистре LFSR(48).
На первый взгляд сделать это невозможно. Однако здесь тоже есть маленькая недоработка в Crypto1.
А именно то, что функция работает только с нечётными разрядами регистра LFSR(48).
То есть мы можем сделать обратное преобразование и из ключевых потоков получить содержимое
регистра LFSR(48) после сдвигов.... А дальше применить сдвиг информации в регистре в обратную
сторону. Ну, это уже совсем просто....
Правда только одной аутентификации для точного расчёта ключа здесь недостаточно.
Обычно надо провести 2 аутентификации или больше.... Поэтому этот способ называется расчётом
по неполным аутентификациям.
Вот так примерно и происходит работа устройства типа SMKey....
Однако, получить информацию от считывателя для расчёта можно и с помощью сниффера
при прикладывании к считывателю исходной метки.
Таким, например, как Proxmark а потом применить программу для расчёта ключей ( Crapto1 ).
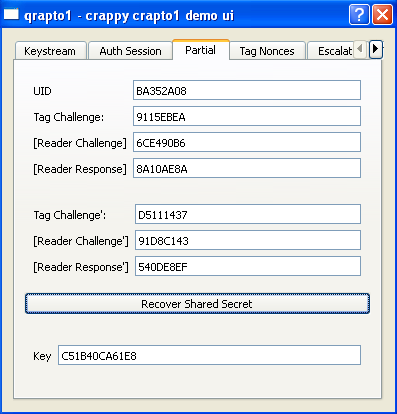
Этот способ обладает одним плюсом - тут можно рассчитывать ключ и на основе полной
аутентификации, и на основе нескольких неполных.....
Кстати, есть ещё одна полезная функция от расчета ключей.
Если надо сделать дополнительные ключи (не копии) для записи в домофон, то можно по UID
этих дополнительных ключей рассчитать ключи доступа на основе неполных аутентификаций.
Ну а далее записать их в трейлеры соответствующих секторов.этих дополнительных ключей.....
То есть можно создавать дополнительные защищённые ключи без ПК со считывателем и карты объекта (КО)..
| 



